Horror Movie Box Office
Little did I know that forecasting movie box office is such a popular (and overused) example when illustrating regression techniques. When I was rummaging through my MBA notes from years ago the other night, I noticed to my chagrin even my professor did a similar exercise and came to similar conclusions. But nothing can dissuade me from doing my part for my favorite movie genre: horror. So here we go…
An Exercise In Frustration?
When we talk about forecasting box office, the time of forecast is important to keep in mind. Being ambitious like most, I simply leaned on IMDB and tried to extract as many features from the website as possible, thinking “How hard can it be?”
If only I had (re)discovered my college professor’s notes, I would see that absent opening weekend box office, the quality of publicly available information on movie productions is lacking at best. Compounding the problem is the various marketing techniques that studios and distribution companies employ, such as limited release simply to build word-of-mouth reputation. The number of screens that the movies will be released on initially is notoriously hard to find. Even more opaque and unreliable is the movie budget these movie sites quote. Who, for instance, can believe that so many movies cost such round numbers like $25 million, to the dollar. Not to mention these budget numbers almost never include the marketing expenses, which for some movies can amount to half of the total production cost.
But soldier on I must and here are a few things (or, the process, to put it more elegantly) I went through.

It pains me to say–so I’ll say it–how many different features I scraped that turned out not to help. A few failed ones include:
- the number of billed actors
- famous names as indicated by the frequency of appearance of said actors (this turned out to be confounding as it was revealed that a lot of the bigger mainstream horror successes were sequels and they would usually employ the same star actors; in this instance being a sequel that followed a success mattered more than innate star power)
- the time distance to the nearest holiday
- content scores as determined by the number of scenes that fall into each of violence, sex and nudity, frightening, drugs and alcohol, and profanity (yes, there are people keeping tabs on this as this information feeds into the MPAA ratings movies receive; interestingly, most of the horror movies are R-rated so the rating itself is almost moot)
To get each of these features, it’s quite time-consuming to identify the right tags to target on the IMDB site. But once found, a little function like the following will do.
def numAwards(strng):
noms = 0
# sometimes major awards are mentioned before
# sometimes there are no nominations or awards
# sometimes there's one not the other
strng = str(strng)
wins = int(re.findall(r'\d+', strng)[0]) # we only need the total so mislabeling noms as wins here is okay
try:
noms = int(re.findall(r'\d+', strng)[1])
except IndexError:
pass
awards = wins + noms
return awards
Which Features to Keep?
To answer the question, I’d employ the wonderful property of lasso regression being able to zero out “non-important” features, defining the following function to examine the coefficients.
def getCoefPolyFeatures(train_data, model_name, desc_n = None):
polynomial_model.get_feature_names()
polynomial_model.get_feature_names(train_data.columns)
features_poly = pd.DataFrame(
{'features': polynomial_model.get_feature_names(train_data.columns), 'coefs': model_name.coef_})
features_poly = features_poly[features_poly.coefs != 0]
features_poly['abs_coefs'] = abs(features_poly['coefs'])
if desc_n is not None:
features_poly = features_poly.sort_values(by='abs_coefs', ascending=False).head(desc_n)
return features_poly
Additionally, to account for interaction terms, sklearn’s PolynomialFeatures would prove useful. Given that statsmodels package does a much better job of reporting diagnostic tests, once I narrowed down to suitable sets of features that were candidates for the final model, I would use the ols funciton from statsmodels.formula.api to generate fit and summaries.
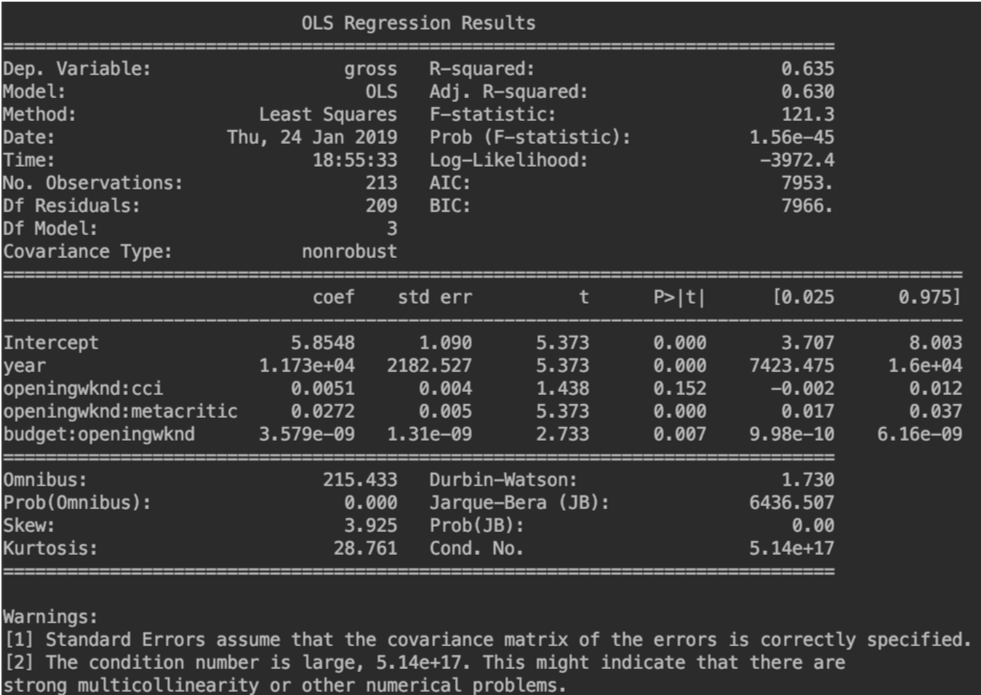
What Were the Findings?
Finally, what ended up being useful were a number of interaction terms between opening weekend box office (yeah, prediction without it was mostly futile) and critic reception score (metacritic) and some wider economic indicator (consumer confidence index). The eventual R-squared on the test set was hardly 0.4, so even with the inclusion of opening weekend, the model left something to be desired.